In solving technical problems, engineers often default to looking only at the technical issues. But sometimes the problems aren’t technical in nature—they’re human-centered. At Nylas, we learned that lesson in our debugging process. Here’s a story of two different bugs and how we dealt with them differently.
tl;dr: Debugging is Tough
Like most companies, we keep a running list of customer issues that have been reported by developers using our API. We use Phabricator, an open-source tool for task management and code review, to track our bugs, and the list can get pretty long at times.
Debugging code is hard. I don’t know how engineers feel about it where you work, but, at Nylas, it’s often been the painful but necessary work that we have to do between feature development and code refactors. I like this quote a lot:
Debugging is twice as hard as writing the code in the first place.
–Brian W. Kernighan and P. J. Plauger
When I was first getting into engineering, I thought that writing the code was the “real work.” But as experienced engineers know, that’s just not true. Sure, you have to write code. But, arguably, the hard part of the job is refactoring and deleting code, thinking of and writing the right test cases, and, of course, debugging issues with the code. A lot of the bugs at Nylas get reported with little to no data about how the users encounter them, and it falls on us as engineers to pull together the scraps of information and identify the root problem, which can take days or even weeks.
However, we’ve learned that there’s a better way to debug issues than what we were doing. Here’s our story of collaborative debugging and how it helped us.
Story Time
Bug #1
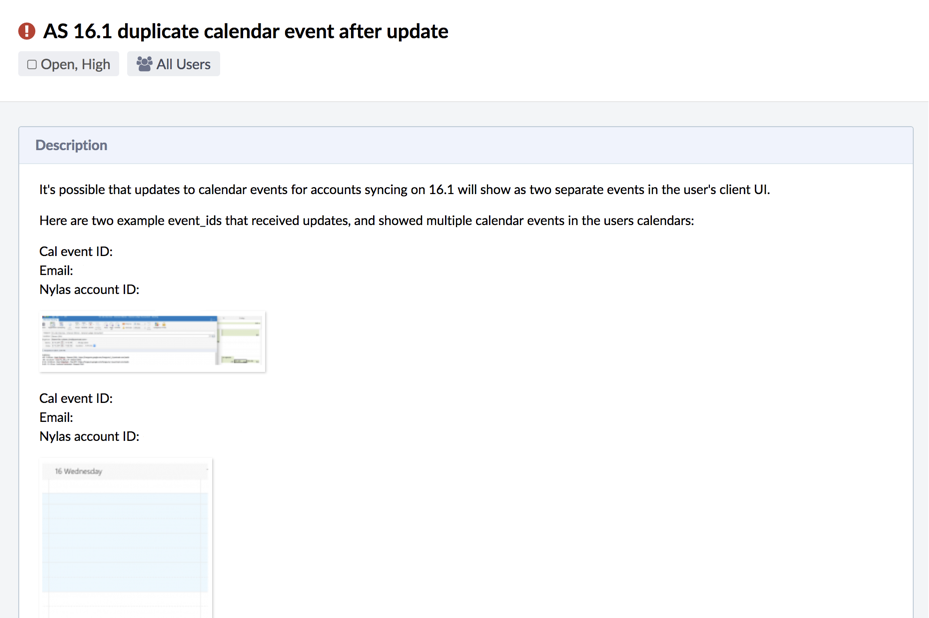
A customer reported that they were experiencing a bug: User A would send User B an update to a calendar invite, and suddenly User B would have duplicate events showing on his calendar.
Here’s the Phabricator task we created:
We had two reports of the bug and a screenshot of someone’s calendar with the duplicate events. Since it was a pretty serious issue for the company using our API, we prioritized it and put it at the top of our “Customer Issues” list.
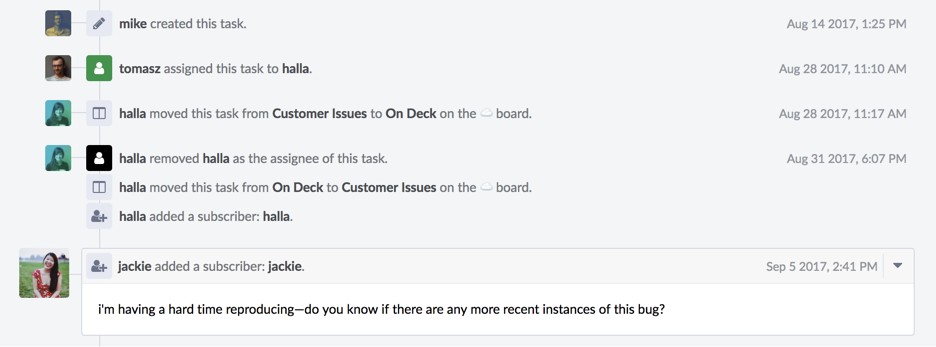
Let’s take a look at the activity on the task:
- We can see that someone created it on August 14 when the bug was reported.
- Two weeks later (August 28), an engineer was assigned to investigate it. She looked into it for a few days and didn’t find a fix.
- The next week (September 5), I was on bug-fixing duty and decided to look into it.
I started with the logs and found nothing. Here’s the first problem: We only keep logs for two weeks, and the bug had been reported a month ago. Next, I spent a good portion of the day seeing if I could reproduce the bug, but didn’t have any luck.
I reported back, letting our support team know that I couldn’t reproduce the bug and needed a recent instance of it or more information in order to investigate further.
Then, I moved on to fix some other bugs and then started working on a different project the next week. Sadly, to date, the duplicate events bug is still happening.*
What was wrong with this process?
First, there was too little information about what the users were doing when they encountered the bug. We needed more data points to be able to reproduce the issue.
The next problem was that we missed the window for checking the logs. Since we only store logs for two weeks, it’s crucial that we address an issue within that fourteen-day window to make sure we can find out where an error is thrown.
The last problem—and in my opinion, the biggest—is that we repeated work. How? Another engineer looked at the problem for three days. Even if she didn’t find a fix, she still investigated, tested a few of her hypotheses, and found out which ones were wrong. But I didn’t have any of that information when I started my investigation.
Later, when I raised this issue at an all-hands, we learned that yet another engineer had looked into this bug but never claimed the Phabricator task because she didn’t find the source of it. We weren’t working collaboratively, and even worse, we weren’t sharing the data we’d gathered because we thought it wasn’t useful.
Enter… Collaborative Debugging
So what does that mean?
We were operating under the assumption that each person should claim a bug and fix it in one stretch. But that’s a faulty assumption for a lot of reasons. A lot of the hardest bugs just don’t work that way. They require longer investigations and multiple people with different knowledge of the codebase looking at the problem.
In addition, it can be really frustrating to work on one bug nonstop for days without making visible progress. Splitting the work allows people to take a break to work on other projects and tag in someone else with a fresh perspective.
If we had been debugging collaboratively, each person would have been leaving breadcrumbs for the next person to make sure progress wasn’t lost along the way.
What could we have done better?
The first answer to this question is the most obvious: we needed to get more information from the user who reported the bug. Collaborative debugging doesn’t just apply to the engineers—you need to collaborate with support as well.
Next, we needed to pull stacktraces from the logs while we were still within that two-week window. That step could be handled by support as part of their ticket creation process. If they look at the logs as soon as they get the bug report and drop the stacktrace for the error into the task they’ve created, then there’s more context for the engineer whenever they’re able to start their investigation.
Finally, the last part is documenting our progress—the good as well as the bad—in the investigation. We had this pervasive idea that the findings from our investigations were only valuable if they led to the root problem. But it turns out, people often have similar thought processes when they’re diagnosing a problem, and as a result, they follow a lot of the same paths. Even if your hypothesis was wrong, it’s useful for the next person to know so that they don’t try to test it again.
Bug #2
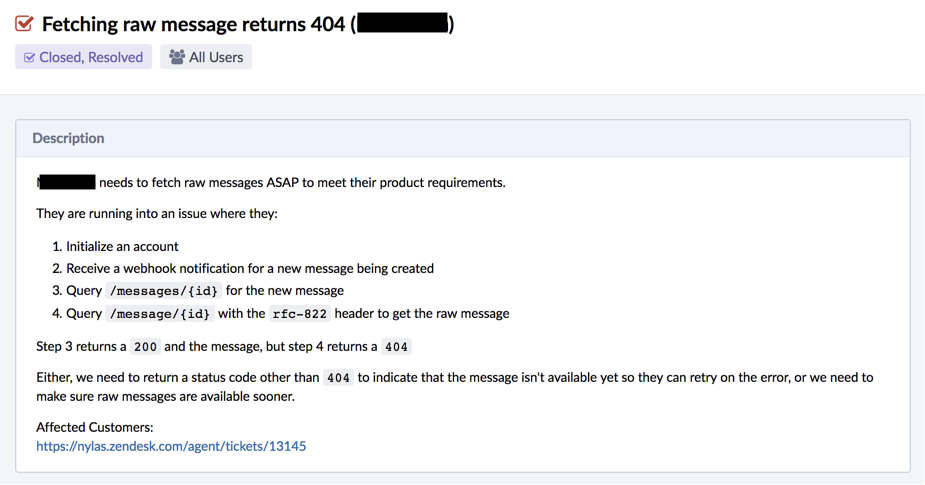
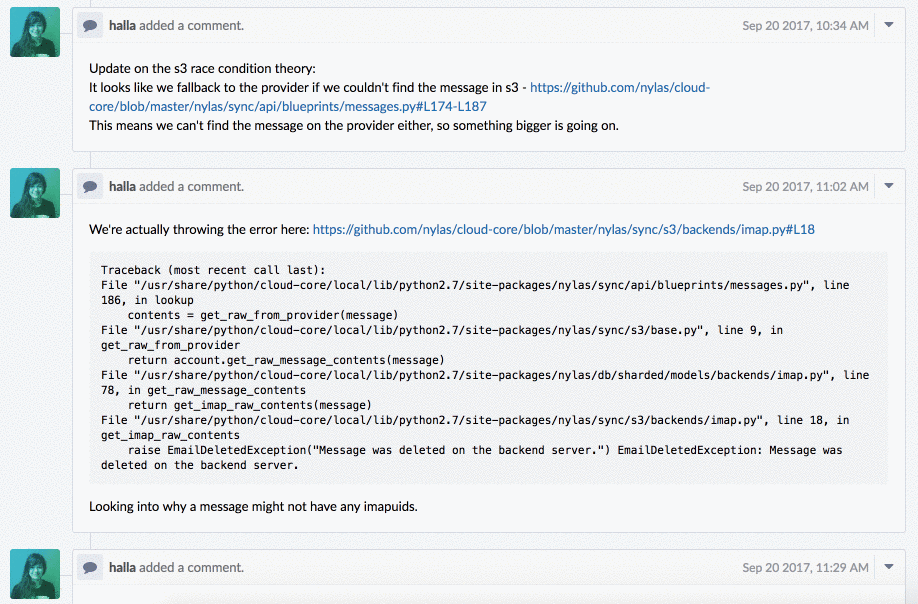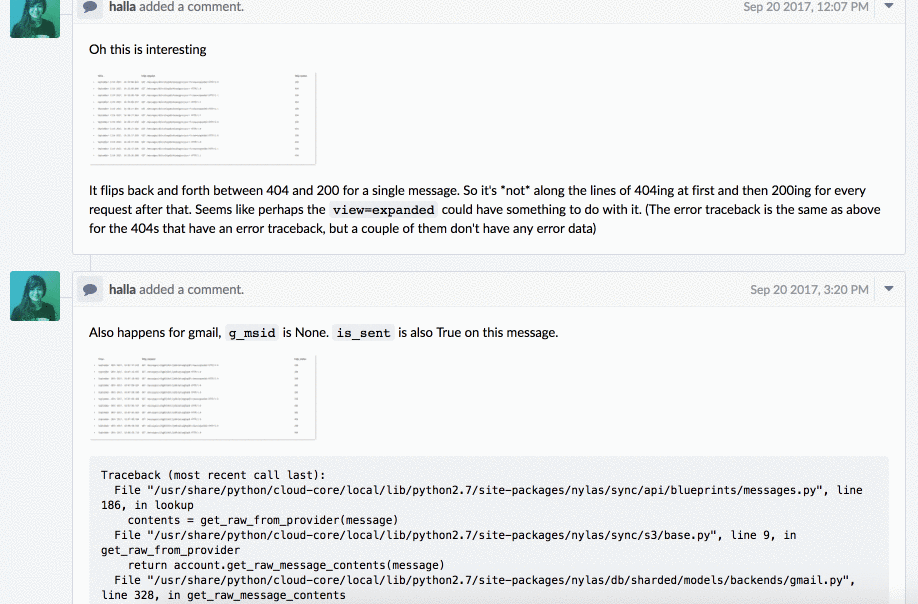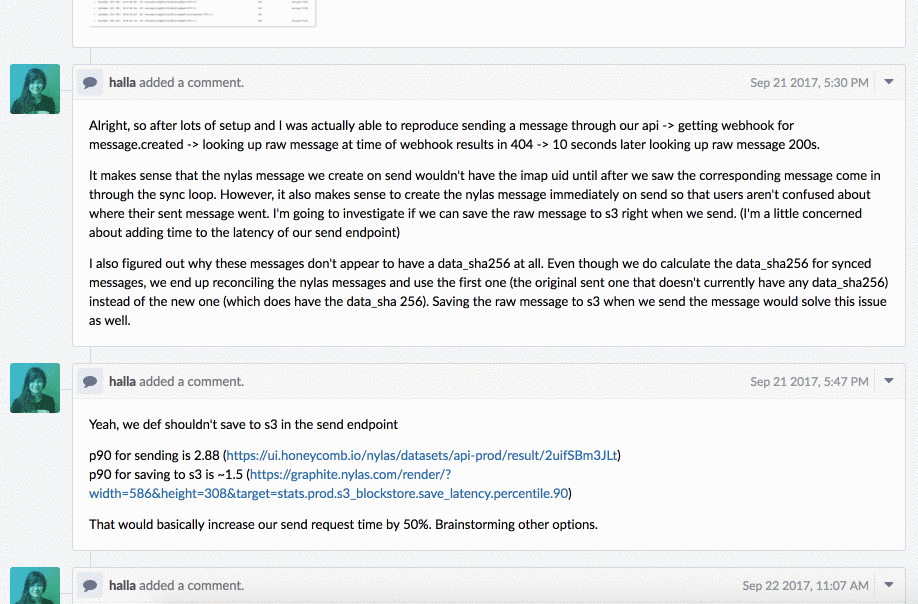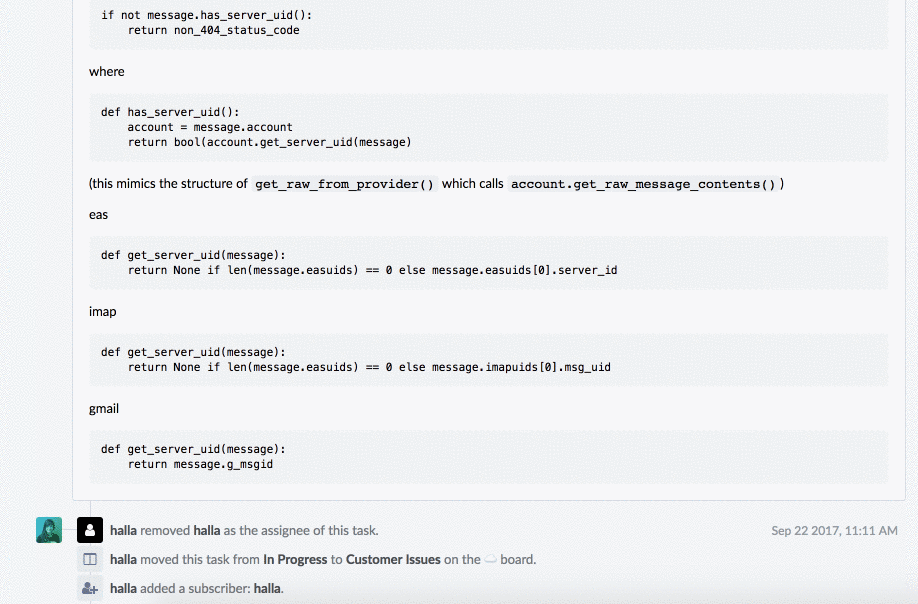
In this second bug, users would send an email through our API, then request the raw MIME message, which we store in S3. Instead of receiving the MIME, they would consistently get a 404 status code.
So here’s the Phabricator task we created:
First, we got the right information from the user. There was a pretty clear four-step process to follow that reproduced the bug. We knew exactly which endpoints they were hitting and what was happening when they did, which was great.
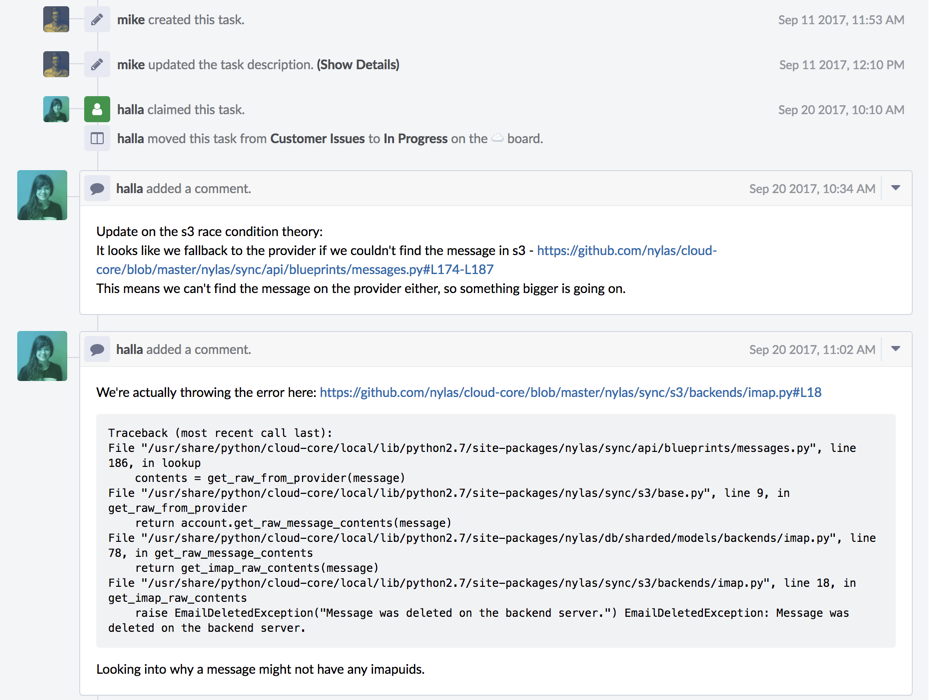
Here’s the initial activity on the task:
We created the ticket on September 11, and an engineer got to it within ten days, so we still had the logs and could find where we were throwing the error. She started investigating and documented her progress. She initially thought it might be a race condition with S3, but that wasn’t the case. Since she documented that hypothesis and explained why it was wrong, it prevented anyone else from going down that dead end in the future.
Here was the course of her investigation:
It took a few days, and she documented all of her thought processes—what she tried, what didn’t work, and eventually what the problem was. After a few days, she had a rough idea of the next steps, but she left for vacation, so I took over the investigation.
As I’m sure you get by now, this handoff usually would have caused some (read: a lot of) frustration, in addition to time wasted, retracing all of the dead ends that she had discovered. However, because I had all of the necessary context, I was able to finish the last part of the investigation, implementing the fix and deploying it without any problems.
Collaborative debugging enabled us to fix this second bug where we couldn’t fix the first one. In addition, we were able to easily carry over work between multiple people. The customer who reported the bug was happy, and we felt really good that we had made progress on the issue.
The Takeaway
The big takeaway from this story is that not every problem is technical in nature. Like most issues, we were inclined to think of this as one that could be solved with a technical solution. We discussed storing the logs for a longer period of time or changing our tooling, but at the end of the day, this issue was a people and process problem. Changing the way we thought about debugging and actively thinking about bug fixes as longer-term, collaborative efforts made the experience a lot better for everyone.
*We’ve since fixed the first bug! ????
 Email and Contacts API
Email and Contacts API  Calendar API & Scheduler
Calendar API & Scheduler  Notetaker API
Notetaker API  Agent Accounts
Agent Accounts